はじめに
もしあなたがRAGを構築し、実際のビジネスシステムに適用したいと考えているなら、「RAGアプリケーションの効果はどうなのか?」「どのように評価するのか?」ということに非常に関心があるでしょう。本記事では、完全なソリューションを提供します。
一般的なRAGアプリケーションの構築プロセスでは、ベクトルデータベースの選択、埋め込みモデルの選択、チャンクパラメータの設定(チャンクサイズ、チャンクオーバーラップ率など)、関連性しきい値、Top-Kなど、多くの問題点が関係してきます。
本記事では主に、RAG評価方法と、オープンソースツールRAGASをベースに、カスタムLLMを使用して評価する方法に焦点を当てています。
Ragについてご紹介します:
LLM RAGとは?
LLM RAGは、Retrieval-Augmented Generationの略称で、日本語では「検索拡張生成」または「取得拡張生成」と訳されます。これは、大規模言語モデル(LLM)と外部知識ソースを組み合わせることで、質問応答(QA)システムや自然言語処理(NLP)タスクの精度を向上させる技術です。
従来のLLMは、膨大な量のテキストデータで学習されたモデルですが、知識の偏りや最新情報の欠如などの問題がありました。一方、RAGは、外部知識ソースから関連情報を検索し、それを基に回答を生成することで、より正確で信頼性の高い回答を提供することができます。
RAGの具体的な動きは以下の通りです。
- ユーザーが入力した質問やプロンプトに対して、LLMが予備的な回答を生成します。
- LLMが生成した予備的な回答に基づいて、外部知識ソースから関連する情報を検索します。
- 検索結果から最も関連性の高い情報を選択し、LLMに提供します。
- LLMは、外部知識ソースから得た情報と自身の知識を基に、最終的な回答を生成します。
RAGの主な利点は以下の通りです。
- 回答精度の向上
- 最新情報の反映
- 事実に基づく回答の生成
- 回答の根拠の明確化
- LLMの知識の偏りの解消
RAGは、QAシステムやチャットボット、文書作成ツールなど、様々なNLPアプリケーションに活用されています。また、近年では、企業独自のデータに基づいた顧客サポートや社内情報検索などの用途にも利用されています。
RAGは、LLMの弱点を補い、NLPの可能性をさらに広げる有望な技術です。今後、RAGの研究開発が進むことで、より自然で人間らしいコミュニケーションを実現できるAIの開発が期待されています。
以下は、RAGに関する参考情報です。
- RAGの解説: LLMとベクトルデータベースを活用したアプローチのまとめ|Kyutaro:https://research.ibm.com/blog/retrieval-augmented-generation-RAG
- LLMを用いたRAGシステムの拡張予測:https://www.ibm.com/blogs/solutions/jp-ja/retrieval-augmented-generation-rag/
- Retrieval-Augmented Generation(RAG)とは? | IBM ソリューション ブログ:https://www.ibm.com/docs/en/watsonx-as-a-service?topic=solutions-retrieval-augmented-generation
- LLMの欠点をRAGで解消!両者の違いや活用方法を紹介:https://www.enterprisebot.ai/blog/overcoming-llm-limitations-with-rag
- 生成AIのトレンド「LLM+RAG」を解説:https://stackoverflow.blog/2023/10/18/retrieval-augmented-generation-keeping-llms-relevant-and-current/
RAG評価方法
RAGの全体的なプロセスには、主に3つの部分が関与しています:入力クエリ、検索されたコンテキスト、LLMの応答です。これらはRAGのプロセス全体で最も重要な3つの要素であり、それらは相互に影響し合っています。したがって、これら3つの要素間の相関性を検出することにより、RAGアプリケーションの効果を評価することができます:

The RAG Triad
- Context Relevance: 検索の質を測定する指標であり、主に、検索されたチャンクがクエリをサポートする度合いを測定します。このスコアが低い場合、クエリの問題と無関係な内容が多く検索されていることを示しており、これらの誤った検索知識はLLMの最終的な回答に一定の影響を与えます。
- Groundedness: LLMの応答が検索されたコンテキストに従う度合いを測定する指標です。このスコアが低い場合、LLMの回答が検索された知識に従っていないことを示しており、回答が幻覚を引き起こす可能性が高くなります。
- Answer Relevance: 最終的な応答がクエリの質問に関連する度合いを測定する指標です。このスコアが低い場合、質問に対して適切に答えられていない可能性があることを示しています。
評価データセットはどのように構築するのでしょうか?
RAGアプリケーションを構築した後、通常はテキストチャンクしか持っていません。では、チャンクのみに基づいて評価データセットを構築するにはどうすればよいでしょうか?答えは、大規模モデルを使用してQAを発掘することです。
もちろん、いくつかのオープンソースツールを使用することもできますし、自分でプロンプトを設計して実装することもできます。このプロセスは難しくありません。単純に「プロンプトエンジニアリング」のプロセスと考えることができます。しかし、どのように行うにせよ、その原理は大まかに次のようになります:

QAPair Mining
評価指標の選択
一般的な評価指標は次のとおりです:
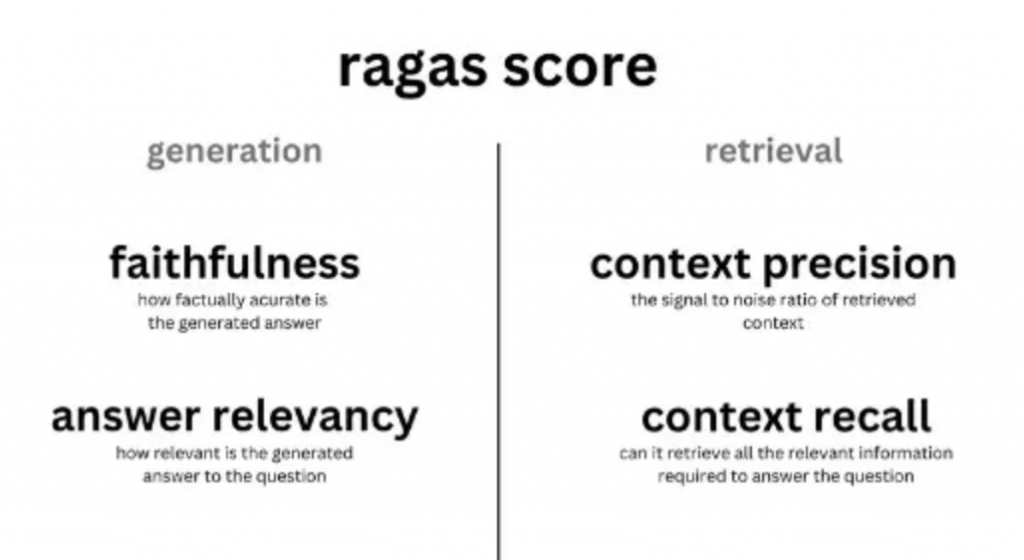
Ragas评测指标
- コンテキストの関連性(Context Relevancy)
この指標は、検索されたコンテキストがクエリをサポートする度合いを測定します。このスコアが低い場合、クエリの問題と無関係な内容が多く検索されていることを示しており、これらの誤った検索知識はLLMの最終的な回答に一定の影響を与えます。RAGASでは、文レベルで関連性を統計しています。計算式は以下の通りです:

Context Relevancy, S为检索到的Context中与query相关的句子
- コンテキストの再現率(Context Recall)
この指標は、検索されたコンテキストが注釈付けされた回答と一致する度合いを測定し、基本的な事実と見なされます。これは基本的な事実と検索されたコンテキストに基づいており、値の範囲は0から1の間で、値が高いほどパフォーマンスが良いことを示します。計算式は以下の通りです:
Context Recall
- コンテキストの精度(Context Precision)
この指標は、検索されたコンテキスト内に存在するすべての基本的な事実に関連するチャンクのランクが高いかどうかを測定します。理想的には、関連するすべてのチャンクが最上位に現れる必要があります。この指標は、クエリとコンテキストを使用して計算され、値は0から1の間で、スコアが高いほど精度が高いことを示します。計算式は以下の通りです:
Context Precision
- 忠実度(Faithfulness/Groundedness)
この指標は、生成された回答と与えられたコンテキストの事実との一貫性を測定します。これは、回答と検索されたコンテキストに基づいて計算されます。回答は(0,1)の範囲に比例してスケーリングされ、値が高いほど良好です。計算式は以下の通りです:
Faithfulness
- 回答の関連性(Answer Relevancy)
この指標は、生成された回答と与えられたプロンプトとの関連性を測定します。不完全または冗長な情報を含む回答は、スコアが低くなります。この指標は、クエリと回答を使用して計算され、値は0から1の間で、スコアが高いほど関連性が良好であることを示します。
RAGASを使用した評価
データのパッケージ化
RAGAS評価では、標準的なDatasetsデータ形式を使用する必要があるため、事前にカスタムデータセットをパッケージ化する必要があります。
from datasets import Dataset questions, answers, contexts, ground_truths = [], [], [], [] # 填充自己的数据内容 evalsets = { “question”: questions, “answer”: answers, “contexts”: contexts, “ground_truths”: ground_truths } evalsets = Dataset.from_dict(evalsets)指標の選択とワンクリック評価
必要な評価指標を選択し、データセットを指定して評価を行います。RAGASはデフォルトでChatGPTを使用しますが、事前にOpenAI APIキーを設定する必要があります。
import os from ragas import evaluate os.environ[“OPENAI_API_KEY”] = “your-openai-key” from ragas.metrics import ( answer_relevancy, faithfulness, context_recall, context_precision, ) result = evaluate( evalsets, metrics=[ context_precision, faithfulness, answer_relevancy, context_recall, ], ) df = result.to_pandas() df.head()RAGASでカスタムLLMを使用する
RAGASはデフォルトでChatGPTを使用しますが、ご存知の通り、様々な理由で使用が制限されています。では、自分のLLMをRAGASフレームワークで評価するにはどうすればよいでしょうか?
以下に、コードを直接示します~
from langchain_community.chat_models import QianfanChatEndpoint from ragas.llms import LangchainLLM from langchain_community.embeddings import QianfanEmbeddingsEndpoint chat = QianfanChatEndpoint(model=model, qianfan_ak=QIANFAN_AK, qianfan_sk=QIANFAN_SK, **model_kwargs) v_llm = LangchainLLM(chat) v_embeddings = QianfanEmbeddingsEndpoint( qianfan_ak=QIANFAN_AK, qianfan_sk=QIANFAN_SK, ) from ragas import evaluate from ragas.metrics import ( answer_relevancy, faithfulness, context_recall, context_precision, ) faithfulness.llm = vllm answer_relevancy.llm = vllm answer_relevancy.embeddings = v_embeddings context_recall.llm = vllm context_precision.llm = vllm result = evaluate( evalsets, metrics=[ context_precision, faithfulness, answer_relevancy, context_recall, ], ) df = result.to_pandas() df.head()参考リンク
- The RAG Triad¶https://www.trulens.org/trulens_eval/core_concepts_rag_triad/
- Get Started Get Started | Ragas
- https://github.com/explodinggradients/ragas
AI時代のChatBot、GPTBaseについて
Sparticleは「生成AIの専業企業として、当社の独自のRAG技術を活用していただけることを光栄に思います。RAG技術の活用により、ChatGPTよりも100%の精度を実現することを目指しており、国内で最高レベルの精度を誇っています。また、「日本語に特化した独自のLLMの提供(国内ベンチマークでは最高レベル)も予定しており、次世代のデジタルモデルであるエージェント(人間をサポートするAI)の実現を目指して参ります」と述べました。
GPTBaseとは
無作為に検索をしないで既存データを利用し最適解を生成します。
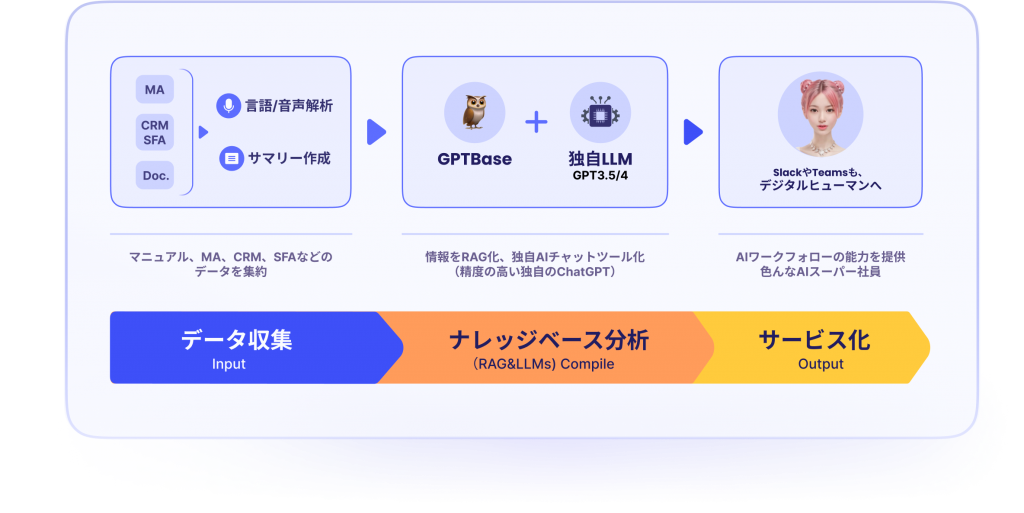
- オンプレミスでの活用が可能です。国内トップレベルの日本語対応LLMでGPTを社内完結!
- 生成AIエンジンを利用します。高精度での多言語対応&事前な会話な対応を実現します!
- AP I連携で自由な利用します。API連携による、既存ツールへの組み込みが可能です!
- 継続的な学習と、精度の向上させます。回答のスコアリングによる、継続した精度の向上を実現します。
GPTBaseの体験リンクはこちら👇
関連記事:
LangChain – RAG: PDFファイルのテーブル型データを抽出する方法について