LangChainとRAGの分野について
LangChainとRAGの分野では、予想通り多くの新しいアイデアが出てきています。
- 例えば、RA-DITはRAGで使用されるLLMを強化し、retrieverを別途トレーニングすることで、LLMの「内部」知識と外部知識の双方向の融合を図ることを目指しています。効果は多少向上しましたが、正直なところ、あまり安定していないようです。
- 「外部知識」の側でretrieval効果を高めるために、LangChainはParentDocumentRetrieverを導入しました。いわゆるParent Document Retrieverは、DocumentとChunkのサイズ間でトレードオフを行うことを意味します。周知の通り、chunkのサイズは最終的に提供されるRAGの効果に非常に重要です。様々なサイズのchunkの間を行ったり来たりして最適な方法を見つけるのではなく、DocumentとChunkの間に別の層を追加することで、異なるサイズが最終的な効果に与える影響を増やすことができます。また、Document内容が変更された際に更新が必要な場合にも、的を絞って更新することができます。以前、我々はDocumentを更新単位にすることができると述べましたが、主にchunkを更新単位にすることは少し面倒だと考えていました。しかし、実際の適用過程で多くの人がDocumentは少し大きすぎると指摘していました。これで中間層が追加されたので、embeddingの更新単位も中間層のサイズに合わせて試すことができます。 😉
- RAGシステムの効果評価については、最近皆さんが非常に注目しているようです。RAGの効果を評価するための専用のRagas(GitHub – explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines)ライブラリもあります。LangSmithもRagasに関していくつかの統合最適化を行っていることがわかります。効果評価は常にLangSmithの主要な方向性でした。そういえば、Debug、Promptのバージョン管理、効果評価、効果比較などの機能は、現在の大規模モデル開発プロセスで必要とされているものです。このブームで「水を売る」ことでお金を稼ぎたい方は、この方向性に注目すると良いでしょう。
アイデアをまとめると、以前の記事でも、RAYフレームワークを使用して複数のPDFファイルの解析とembeddingを最適化する方法について述べました。実際、大規模モデルアプリケーションの実装における3つのステップは次の通りです。
Phase I:
RAG Phase II:プライベートFTモデル
Phase III:ビジネスロジックを深く統合したエージェント
始めるのが一番難しいものですが、この3つのステップの中で、企業内でRAGをスムーズに導入することは難しい課題です。PDFなどの企業内データを正しく解析し、次のステップであるembedding化、embの効率的な保存、embの柔軟な更新を行うことは、この一連の難しい課題の中でも特に難しいものです。特に、ドキュメントにテーブルが含まれている場合、さらにそれらのテーブルが画像の形で存在している場合は、注意しないとテーブル内の情報が分散してしまいがちです。先頭と末尾を切り取ってembeddingに使用すると、良い結果が得られないだけでなく、RAGに悪影響を及ぼす可能性があります。解決方法としては、テーブル情報を専門的に保存、デコード、embedding処理することが考えられます。画像の場合はOCRを使用するしかありません。情報保存の部分では、LangChainが2ヶ月前にリリースしたMultiVectorRetrieverがこの問題に対応しています。後者については、unstructured.ioのようにtesseractをラップしたものを使用します(もちろん、最新のものを試してみたい場合は、Metaが8月末にリリースしたnougatを試してみるのも良いでしょう)。例を挙げると以下のようになります。

環境構築:
- Ubuntu環境でtesseractをインストール:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev- Ubuntu環境でpopplerをインストール:
sudo apt-get install poppler-utils- unstructured など:
pip install langchain unstructured[all-docs] pydantic lxml langchainhub openai chromadb tiktoken- 実験対象PDF:
wget -U xxx https://arxiv.org/pdf/2307.09288.pdfコード・処理ロジック:
path = “./“ from lxml import html from pydantic import BaseModel from typing import Any, Optional from unstructured.partition.pdf import partition_pdf # Get elements raw_pdf_elements = partition_pdf(filename=path+”2307.09288.pdf”, # Unstructured first finds embedded image blocks extract_images_in_pdf=False, # Use layout model (YOLOX) to get bounding boxes (for tables) and find titles # Titles are any sub-section of the document infer_table_structure=True, # Post processing to aggregate text once we have the title chunking_strategy=”by_title”, # Chunking params to aggregate text blocks # Attempt to create a new chunk 3800 chars # Attempt to keep chunks > 2000 chars max_characters=4000, new_after_n_chars=3800, combine_text_under_n_chars=2000)OCRを使用しているため、この処理には非常に長い時間がかかります。Colabでは、77ページの処理に14分を要しました。1ページあたり平均11秒の計算になります。

Unstructuredライブラリで解析できるコンテンツを概観してみると、テキストとテーブルの両方が含まれていることがわかります。
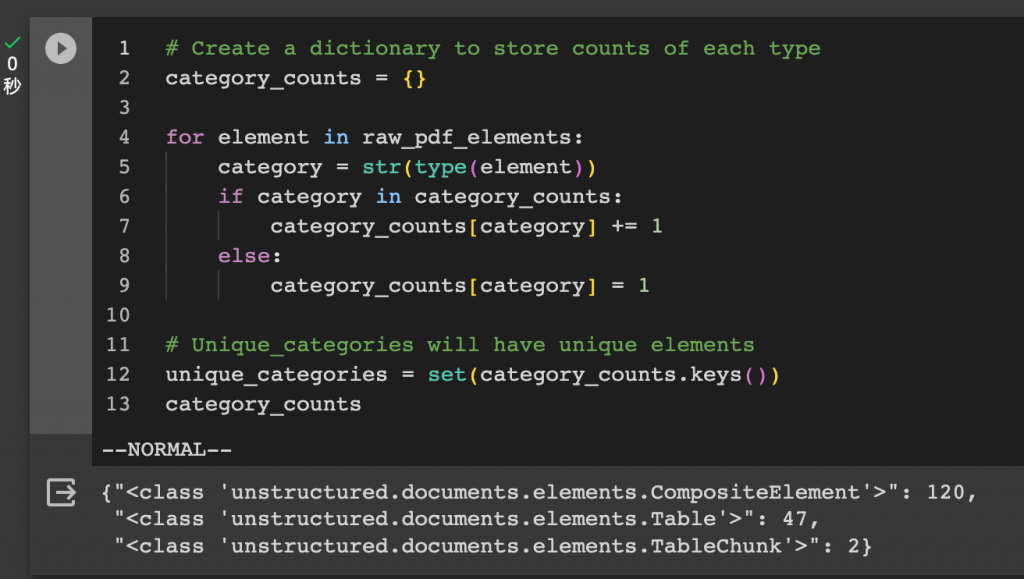
テキストとテーブルのコンテンツを分けて保存し、後の処理に備えます。
class Element(BaseModel): type: str text: Any # Categorize by type categorized_elements = [] for element in raw_pdf_elements: if “unstructured.documents.elements.Table” in str(type(element)): categorized_elements.append(Element(type=”table”, text=str(element))) elif “unstructured.documents.elements.CompositeElement” in str(type(element)): categorized_elements.append(Element(type=”text”, text=str(element))) # Tables table_elements = [e for e in categorized_elements if e.type == “table”] print(len(table_elements)) # Text text_elements = [e for e in categorized_elements if e.type == “text”] print(len(text_elements) ## output: # 49 # 120LangChainの基本パッケージをインポートします。
from langchain.chat_models import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain import hub obj = hub.pull(“rlm/multi-vector-retriever-summarization”)ここでは、langchain-hubにあるコミュニティ提供のプロンプトを導入し、具体的にどのように書かれているかを見てみましょう。

LCELを使用してチェーンを組み立てます。3.5を使用すると効果が大きく影響を受ける可能性があるため、可能であれば4を使用しましょう。
# Summary chain prompt = ChatPromptTemplate.from_template(obj.template) model = ChatOpenAI(temperature=0,model=”gpt-4″) summarize_chain = {“element”: lambda x:x} | prompt | model | StrOutputParser()ここでは、LCELというDSLを使用して各コンポーネントを連結することで、非常に見栄えの良いものになっていることがわかります!
要約チェーンを組み立てたら、テキストとテーブルの情報をそれぞれ抽出することができます。
# Apply to texts texts = [i.text for i in text_elements] text_summaries = summarize_chain.batch(texts, {“max_concurrency”: 5} # Apply to tables tables = [i.text for i in table_elements] table_summaries = summarize_chain.batch(tables, {“max_concurrency”: 5}
次に、テキストとテーブルの情報をそれぞれLangChainのマルチベクトルレトリーバーに追加します。
import uuidfrom langchain.vectorstores import Chromafrom langchain.storage import InMemoryStorefrom langchain.schema.document import Documentfrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.retrievers.multi_vector import MultiVectorRetriever# The vectorstore to use to index the child chunksvectorstore = Chroma(collection_name="summaries",embedding_function=OpenAIEmbeddings())# The storage layer for the parent documentsstore = InMemoryStore()id_key = "doc_id"# The retriever (empty to start)retriever = MultiVectorRetriever(vectorstore=vectorstore,docstore=store,id_key=id_key,)# Add textsdoc_ids = [str(uuid.uuid4()) for _ in texts]summary_texts = [Document(page_content=s,metadata={id_key: doc_ids[i]}) for i, s in enumerate(text_summaries)]retriever.vectorstore.add_documents(summary_texts)retriever.docstore.mset(list(zip(doc_ids, texts)))# Add tablestable_ids = [str(uuid.uuid4()) for _ in tables]summary_tables = [Document(page_content=s,metadata={id_key: table_ids[i]}) for i, s in enumerate(table_summaries)]retriever.vectorstore.add_documents(summary_tables)retriever.docstore.mset(list(zip(table_ids, tables)))テーブル情報の抽出と要約の効果を簡単に見てみましょう。

RAGを組み立てます!
from operator import itemgetterfrom langchain.schema.runnable import RunnablePassthrough# Prompt templatetemplate = “””Answer the question based only on the following context, which can include text and tables: {context} Question: {question} “””prompt = ChatPromptTemplate.from_template(template)# LLMmodel = ChatOpenAI(temperature=0)# RAG pipelinechain = ({“context”: retriever, “question”: RunnablePassthrough()}| prompt| model| StrOutputParser()なるほど、言われてみれば確かにその通りですね。まとめると以下のようになります。
- モデルに3.5を使用すると、効果が大幅に低下します。上記の実験を参照してください。
- マルチベクトルレトリーバーでテーブル情報を個別に処理するのは非常に優れています!
- OCRはリソースを大量に消費するため、事前にマークダウンに変換しておけば、効率が大幅に向上すると思われます。
次回は、RAGの効果評価に関する内容をまとめる予定です。
AI時代のChatBot、GPTBaseについて
Sparticleは「生成AIの専業企業として、当社の独自のRAG技術を活用していただけることを光栄に思います。RAG技術の活用により、ChatGPTよりも100%の精度を実現することを目指しており、国内で最高レベルの精度を誇っています。また、「日本語に特化した独自のLLMの提供(国内ベンチマークでは最高レベル)も予定しており、次世代のデジタルモデルであるエージェント(人間をサポートするAI)の実現を目指して参ります」と述べました。
GPTBaseとは
無作為に検索をしないで既存データを利用し最適解を生成します。
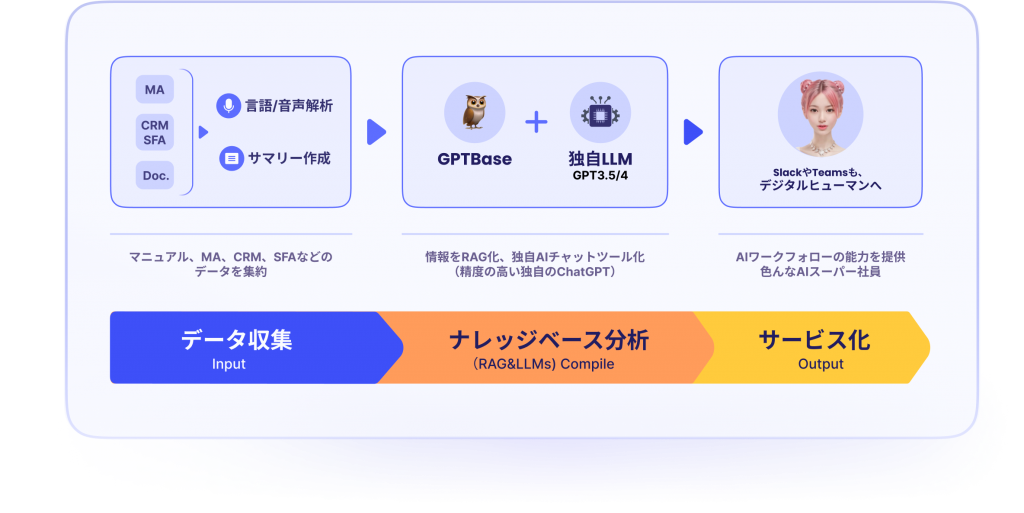
- オンプレミスでの活用が可能です。国内トップレベルの日本語対応LLMでGPTを社内完結!
- 生成AIエンジンを利用します。高精度での多言語対応&事前な会話な対応を実現します!
- AP I連携で自由な利用します。API連携による、既存ツールへの組み込みが可能です!
- 継続的な学習と、精度の向上させます。回答のスコアリングによる、継続した精度の向上を実現します。
GPTBaseの体験リンクはこちら👇
関連記事:
RAG効果の評価について:カスタムLLMを使用したRAGアプローチの評価