
大规模语言模型(LLM)是利用大量文本数据和深度学习技术构建的语言模型。与传统语言模型相比,显着增加了以下三个要素:
- 计算:允许更高级的处理和更复杂的任务。
- 数据量:学习更多的语言模式,生成更自然、更人性化的句子。
- 参数数量:提高模型精度并使其更加通用。
这些特性使得LLM能够在各种自然语言处理(NLP)任务中表现良好。
Transformer如何运作
1.变压器架构
LLM 底层的神经网络架构称为Transformer 。 Transformer 由 Google AI 于 2017 年开发,相比传统 RNN(循环神经网络)架构具有以下优势:

- 处理远程依赖关系:Transformer 非常适合理解和生成长句子,因为它可以有效地处理句子之间的关系。
- 并行处理:Transformer可以并行处理计算,从而获得更快的处理速度。
- 可扩展性:Transformer 可以在大型数据集上学习,使其适合 LLM。
Transformer由两个主要组件组成:编码器和解码器。
- 编码器:处理输入句子并生成表示单词之间关系的向量。
- 解码器:根据编码器输出的向量预测下一个单词并生成句子。
编码器和解码器使用一种称为自注意力的机制来学习句子之间的关系。自注意力计算每个单词与其他单词的关系,并帮助您理解上下文。
2.海量学习数据

LLM是使用大量文本数据进行训练的。训练数据包括书籍、文章、新闻、网站等各种文本。法学硕士拥有的数据越多,它可以学习的语言模式就越多,并生成更自然、更接近人类的句子。
近年来,监督学习和自监督学习相结合的LLM学习方法已成为主流。
- 监督学习:使用带有真实标签的数据训练模型。
- 自监督学习:模型通过使用未标记的数据自行估计标签来进行学习。
通过结合这些学习方法,LLM可以从更多数据中学习并提高准确性。
3.先进的深度学习技术

LLM使用Adam和RMSprop等高级优化算法以及Dropout和L2 正则化等正则化技术进行训练。这些技术有助于提高模型准确性并减少过度拟合。
LLM有时也会使用TPU (张量处理单元)等专用硬件进行训练。 TPU 可以比传统 CPU 和 GPU 更快地处理计算,这可以显着减少 LLM 训练时间。
LLM商业应用领域
LLM应用于各个业务领域。主要使用示例如下。
- 客户服务:自动化客户与聊天机器人和语音识别系统的交互
- 内容创作:自动生成广告文字、文章、博客文章等。
- 翻译:语言之间的翻译
- 搜索:提高搜索结果的准确性
- 营销:根据客户需求定制广告投放
- 开发:软件代码生成
除了这些使用示例之外,LLM 还具有在各个领域应用的潜力。
琐事:使用 LLM 的服务
LLM 已用于多种服务中。例如,LLM用于谷歌翻译和亚马逊Alexa等语音识别系统。
法学硕士的挑战
虽然LLM是一个非常强大的工具,但它也存在一些挑战。
- 偏差:LLM 可以反映训练数据中的偏差。
- 道德:LLM 生成的文本可能包含道德上有问题的内容。
- 责任:解释法学硕士决策的基础可能很困难。
为了克服这些挑战,需要制定法学硕士开发和使用的道德准则。
LLM的未来展望
LLM未来有望进一步发展。随着研究和开发的进展,法学硕士可能会变得更加复杂,并且能够与人类自然地交流。法学硕士还有潜力创造新的商业模式和服务。
LLM在未来将会越来越融入我们的生活。
外语高效沟通,精准的AI实时翻译工具——Felo 实时翻译
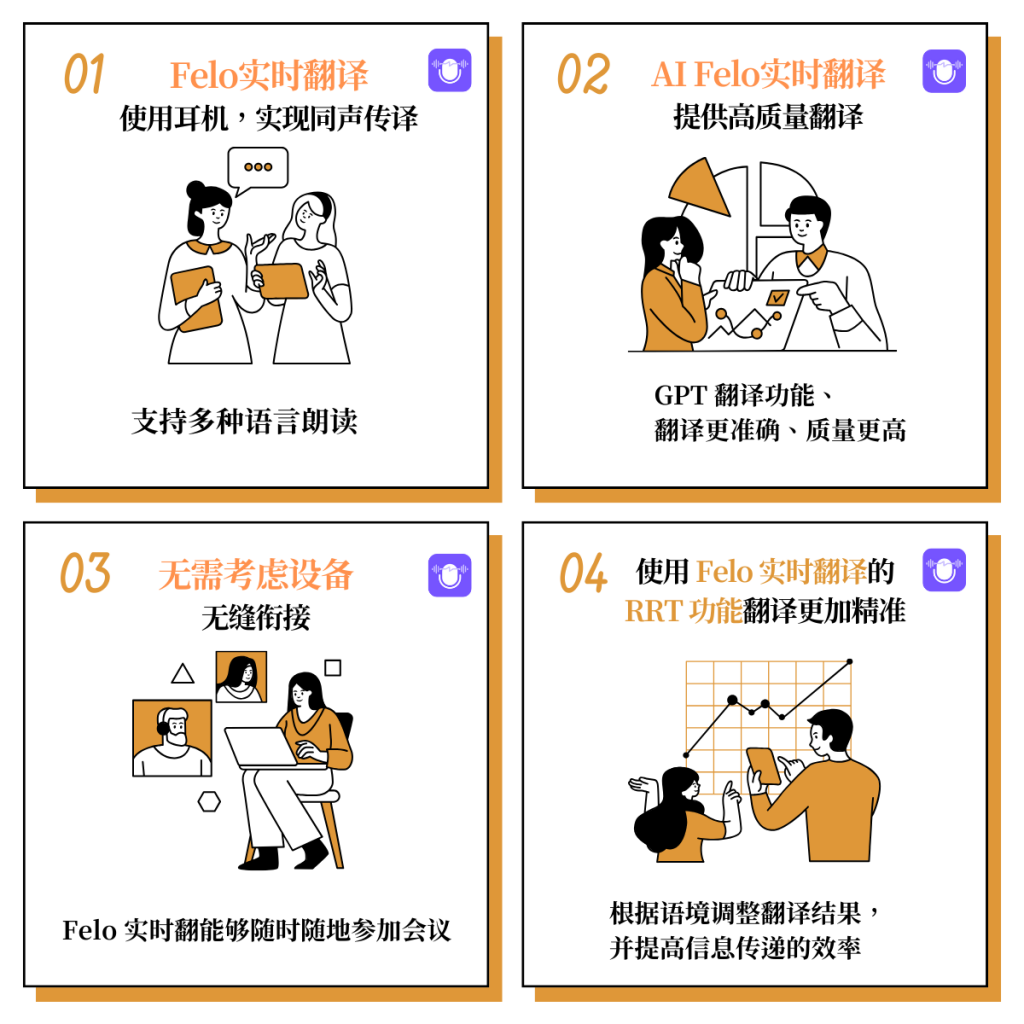
什么是Felo 实时翻译?
Felo实时翻译是一款AI同声传译APP,搭载GPT-4引擎和RRT技术,它能够快速且正确地翻译15种以上外语(包括英语、西班牙语、法语、德语、俄语、中文、阿拉伯语和日语等)的语音,支持下载原文和译文文本,帮助你学习地道的表达方式和发音。
Felo 实时翻译可以帮助到同声传译什么?
它可以辅助刚入门同声传译的同学,解决跟不上记录,专业词汇翻译更佳准确。
同声传译是一项复杂而技术性强的工作,需要译员具备扎实的语言功底、丰富的专业知识和良好的团队合作精神。只有不断地学习和提升自己的翻译能力,才能够胜任这一重要的翻译任务,为国际交流的顺利进行做出贡献。
更多相关链接
(06)Glarity新功能解读:总结Gmail邮件&快速回复 – 让写作更简单